社内文書を対象とした Agentic RAG コンペ(SIGNATE)に取り組んだ記録です。
方針から設計、実装の2経路(API版と完全ローカル版)、現場で踏んだ罠、PDCA、工夫まで、一本で追えるようにまとめました。
これから同種のシステムを作る人が、読んでそのまま再現できることを目指して作成しました。
長編です。笑
課題は、架空のデータ分析コンサル会社「データアステル社」の共有ドライブを対象に、寄せられる質問へ根拠に基づいて日本語で回答する RAG システムを作り、回答精度を競うものです。

今回のRAG コンペにおいて重要視されている点としては、
新規の案件フォルダ・新規の資料の追加によって、回答精度が変わらないこと。
つまり「既存データによって最適化された検索」ではなく、「未知のデータでも同じ検索結果を出力する汎用システムを作る」ことがゴールとなります。
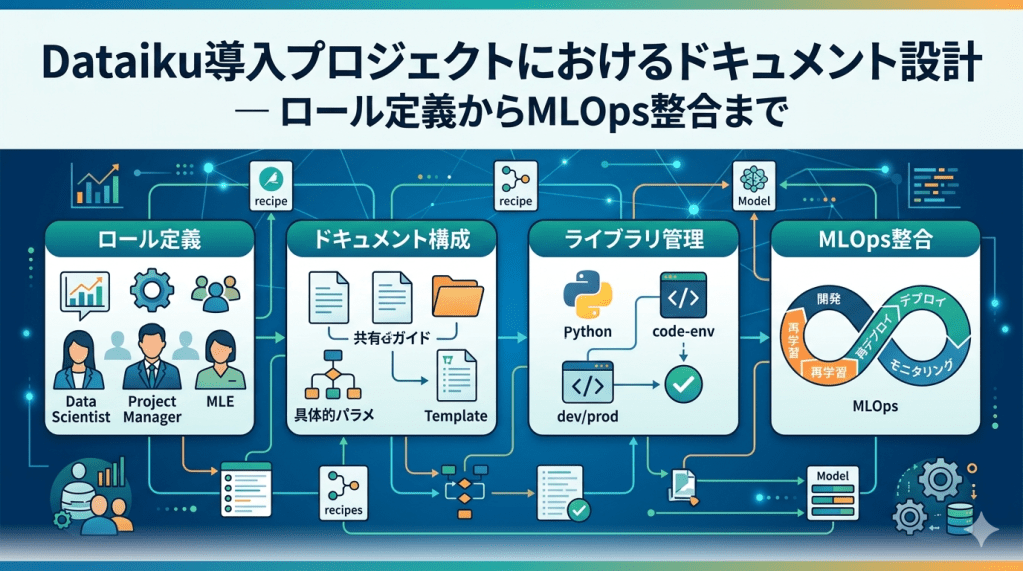
0. 全体アーキテクチャ
まず完成形の全体像です。Store / Retrieve / Agent / Output の4層構成で、LLM バックエンドは OpenAI API とローカル Ollama を設定1つで切り替えられます。
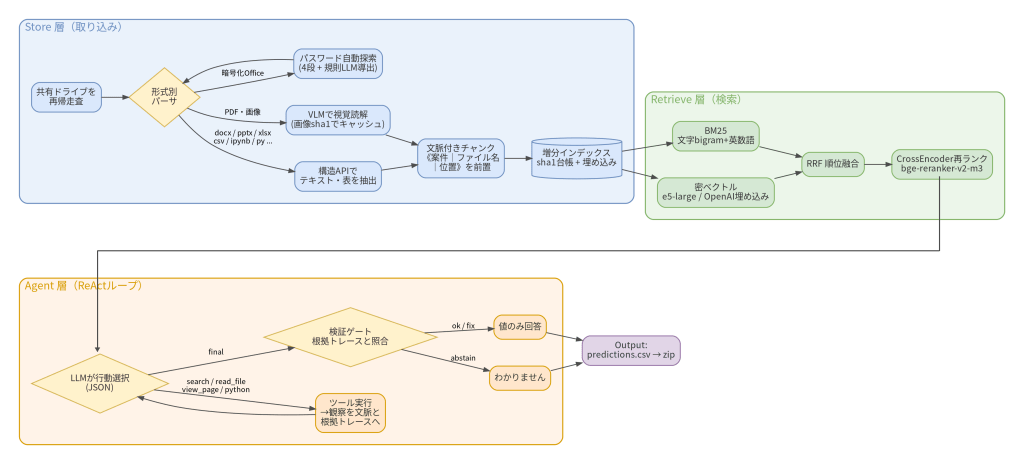
この構成に至るまでの判断を、順に説明していきます。
1. 方針 — コードより先に、評価コードと論文を読む
最初に着手したのは実装ではなく、配布された評価コードの解読でした。
1-1. 採点 LLM は「質問文を見ない」
本コンペの評価は Meta の CRAG ベンチマーク [1] に準拠した LLM 採点で、回答を Perfect(+1) / Acceptable(+0.5) / Missing(0) / Incorrect(-1) に分類し、平均をスコアとします。評価コードを読むと、採点プロンプトに渡されるのは
ground_truth: {模範解答} answer: {提出回答}
のみで、質問文は渡されません。「契約金額はX円です。契約書第5条に記載され…」のような丁寧な回答は、模範解答「X円」との文字列比較で不利になり得ます。回答は”値そのもの”だけを、模範解答と同じ形式で出すのが最適解となります。
1-2. 得点の非対称性から「賭け方」を決める
| 判定 | 得点 | 条件 |
|---|---|---|
| Perfect | +1 | 完全に正しい |
| Acceptable | +0.5 | 軽微な誤りのみ(数値は指定桁への丸め一致に限る) |
| Missing | 0 | 「わかりません」等の無回答 |
| Incorrect | -1 | 誤り・無関係 |
重要な非対称性が2つ。要素列挙問題は部分一致でも即 Incorrect(-1)、Acceptable なし。そしてMissing は 0 点。誤答の -1 に対し、自信がないときの「わかりません」は 0 で止血できます。
1-3. 方針の4原則
- 評価仕様からの逆算 — 回答は値のみ・1行・列挙は「、」区切り・不確実なら「わかりません」
- 汎用性最優先 — フォルダ名・ファイル名・値からのハードコードをなくす。実行時にドライブから機械検出を行う。
- 検索+計算 — 「CSV を条件抽出して集計」「版間差分」型の問題が確実に存在。LLM の暗算ではなくコード生成+実行で計算
- 再現性 — temperature=0・seed 固定・全 LLM 呼び出しの JSONL ログ・使用モデル名の記録
2. 設計 — 4層それぞれの中身
2-1. Store — パース品質が RAG 全体の性能を決める
「OCR・パースの品質が下流性能をどれだけ律速するか」は OHRBench が体系的に示した論点で、Store の手抜きは後段で取り返せないという本設計の前提を裏付けます。本件は配布データが Office 系中心(構造化 API で正確に読める)なので、pptx/docx/xlsx はライブラリで直接パースし、PDF・画像のみ VLM 読解に回すハイブリッドにしました。
画像・グラフの扱いは設計の分岐点でした。ページ画像そのものを検索対象にする方式と、VLM でテキスト化してからテキスト検索に載せる方式がありますが、本パイプラインは後者を採りました。(a) 既存の BM25+密ベクトル・増分インデックスをそのまま活かせる、(b) 生成キャプションを画像バイト列の sha1 でキャッシュでき再実行時の再課金・再計算がゼロ、(c) 重い検索モデルを持ち込まずに済む、が理由です。ページ画像検索の利点は、後述の view_page ツールで補完します。
インデックスは増分設計です。ファイルごとの台帳を持ち、追加・変更分だけをパース・埋め込みします。「新規フォルダを追加しても既存チャンクの埋め込みが1ビットも変わらない」ことをテストで実証しており、検収時のデータ追加が既存の検索品質を揺らさない根拠になっています。
失敗したファイル(未復号・画像読解失敗)は台帳に載せない=次回実行時に自動リトライという一貫した規則で、中断・再開にも同じ仕組みで対応します。
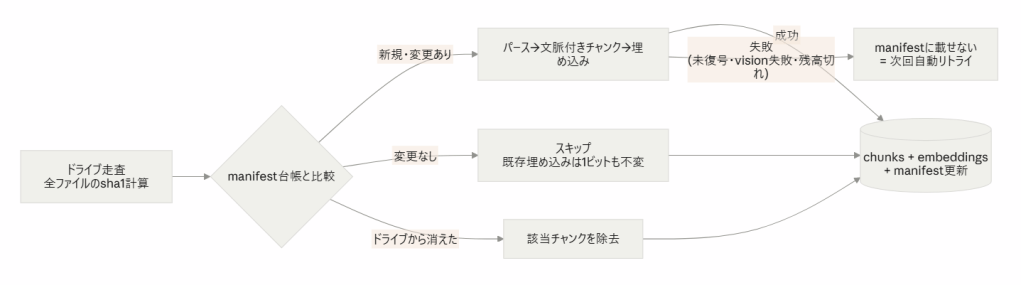
さらに各チャンク本文に 《案件名|ファイル名|位置》 という出典コンテキストを前置してから索引化します。チャンク単体で失われる文書レベルの文脈を埋め込み・BM25 双方に効かせるこの手法は、Anthropic の Contextual Retrieval の軽量版です。原典は LLM でチャンクごとの説明文を生成しますが、メタデータの機械的前置だけでも「案件名+項目名」型クエリのマッチが明確に改善しました。
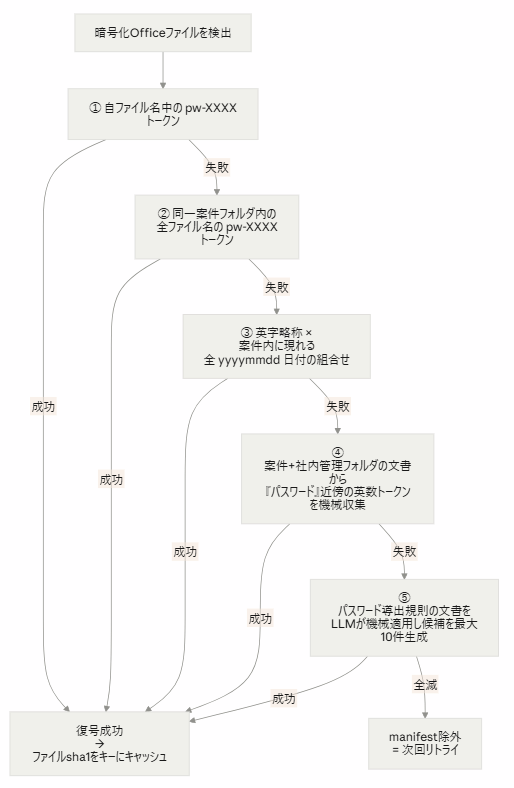
暗号化 Office ファイルへの対応は、ハードコード禁止下では「実行時にドライブから候補を機械生成して試す」一択です。候補生成は4段+LLM導出の5段構えにしました。⑤が効くのは「パスワードそのものはどこにも書かれていないが、導出規則の文書は存在する」ケースです。規則文書の内容は実行時に読むため、新規案件にも同一処理で一般化されます(特定パスワードの埋め込みではないのでルール適合です)。
2-2. Retrieve — スコアではなく「順位」で融合する
日本語×専門用語×英字識別子(列名やタスクID)が混ざるコーパスなので、キーワード検索(BM25、形態素解析器なしで動く文字 bigram+英数語トークナイザ)と意味検索(埋め込み)のハイブリッドにし、RRF(Reciprocal Rank Fusion) で融合しました。
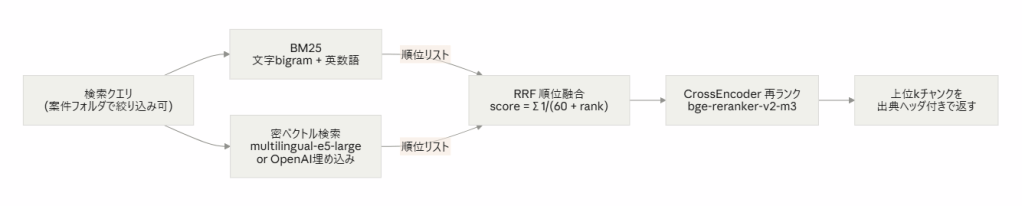
RRF は学習不要・スコア校正不要で個別ランカーを上回るという原論文の性質が「新規フォルダ耐性」に直結します。BM25 のスコア分布はコーパス増加で変わりますが、順位ベースの融合はスケール変化に影響されません。
2-3. Agent — 静的パイプラインではなくツールループ
「検索して詰めて生成する」静的 RAG に対し、計画・ツール使用・自己修正を行う Agentic RAG の枠組みは Singh らのサーベイ に整理されています。本件は単一資料の読解から複数案件の照合・集計まで難度の幅があり、固定フローでは過不足が出ます。そこで ReAct 型の「思考→行動→観察」ループに6つのツールを持たせました。
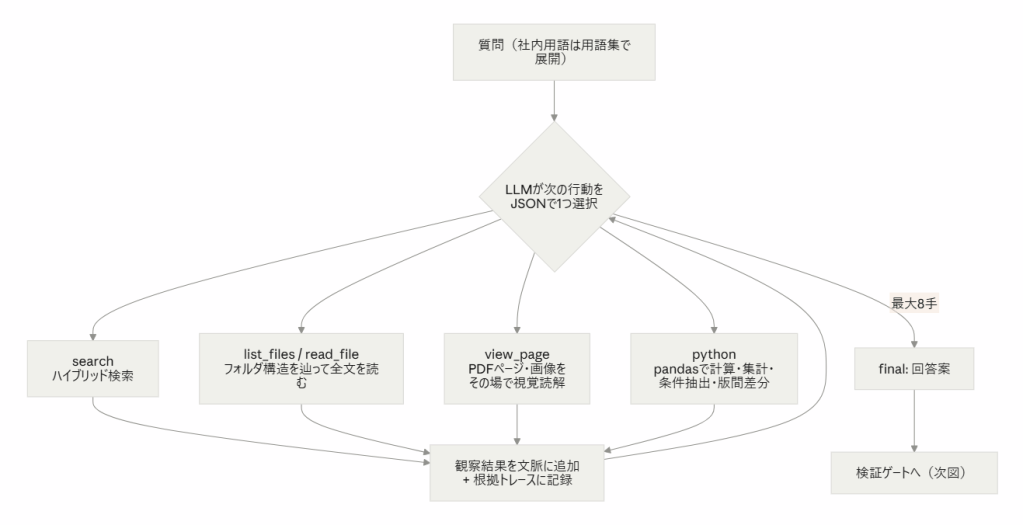
list_files / read_file で構造メタデータを辿ってから中身に踏み込む設計は PDFTriage と同じ発想。計算を LLM にさせず python へ委譲するのは PAL / PoT の直系です。view_page は M3DocRAG・ViDoRAG が示した「曖昧なときはページを直接見る」能力の実装で、キャプション索引(安価・網羅)とページ直接参照(高精度・オンデマンド)の二段構えになっています。
日本語パス照合の落とし穴は、(1) NFC→実パスのマップを起動時に構築、(2) python ツールに正規化差異を吸収する find("キーワード", suffix=".csv") ヘルパーを注入、の2段でシステム側に吸収しました。エージェントが生成するコードも必ず踏む罠だからです。
2-4. 検証ゲート — 「出す前に、根拠と突き合わせる」
最重要の安全弁が final 直前の根拠ゲート付き検証です。ループ中に蓄積した「根拠トレース」と回答案を照合する検証 LLM を1回だけ呼び、採点の非対称性(誤答-1/棄権0)を明示したうえで判定させます。
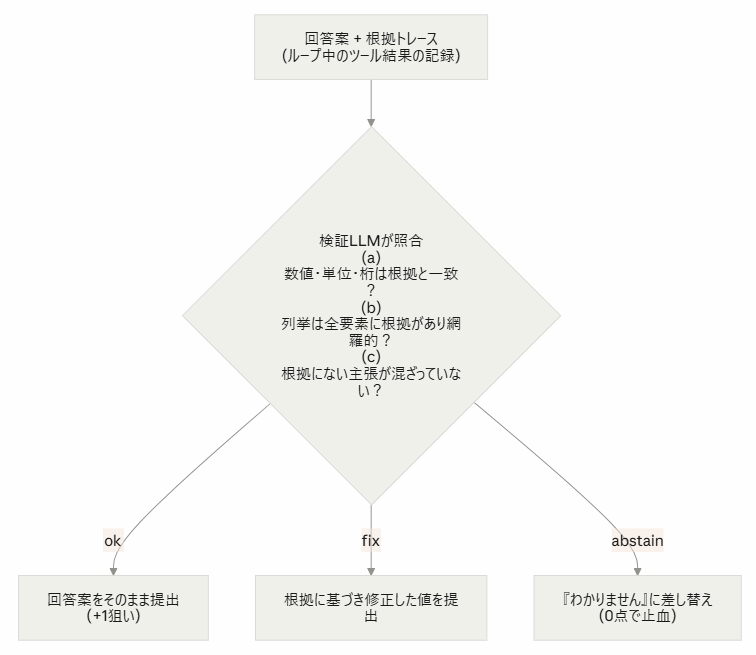
生成後に自己批評・修正を挟む設計は Self-RAG 、Corrective RAG 、CRAG-MM 上位解の検証中心アーキテクチャに連なります。特に列挙問題(部分一致=-1)への「1要素でも怪しければ棄権」は、期待値上もっとも効く場所に置いた安全弁です。後述のローカル 7B 構成では、モデルが弱くなるほどこのゲートの価値が上がります。誤答 -1 を量産する代わりに棄権 0 で守れるためです。
3. マルチエージェントや FastMCP は使うべきか
設計中に検討し、どちらも採用しませんでした。判断基準は一つ、「その仕組みがこの採点仕様で期待スコアを上げるか」です。
FastMCP はツールをプロセス外のクライアントに公開する仕組みですが、本コンペの実行モデルは「predictions.csv を作る単一プロセスを審査側が再現できること」で、公開する相手がいません。挟むと通信・サーバ起動・スキーマ層が増え、再現性を損ない障害点が増えるだけ。これは「運用化フェーズ」の選択肢です。
マルチエージェントの利点(コンテキスト分離・並列化) は、本件では別手段で達成済みでした。案件ごとの情報分離は search(folders=[...]) のフォルダ絞り込みで、集計の正確性は pandas への委譲で担保。むしろエージェントを増やすと出力のばらつき・伝言ゲームの劣化・再現性低下・呼び出し数の増加を招きます。誤答 -1 を避けたいタスクでは「単一の統制されたループが、根拠を確かめてから、怪しければ棄権する」ほうが期待値が高く、CRAG 系上位解 も制御性重視の比較的単純な構成でした。
4. 実装 — 2つの実行経路(API版/完全ローカル版)
本体は単一の rag_pipeline.py(約1,500行)で、LLM 呼び出しを1つのクラスに集約してあります。そのため実行経路は設定1つで切り替えられます。
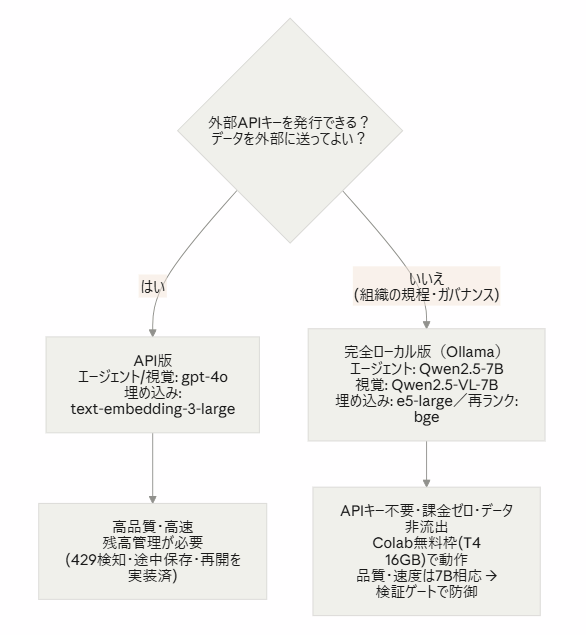
4-1. API 版(OpenAI)
OPENAI_API_KEY を設定し、Colab または任意の Python 環境で「Drive マウント → ZIP 展開 → パス確定 → インデックス構築 → 検証30問 → 本番100問 → zip」の順に実行します。残高切れ(429 insufficient_quota)は専用例外として検知し、インデックス構築・回答生成のどちらでもそこまでの成果を保存して中断→残高補充後に同じセルを再実行すれば差分から再開されます。構築前には estimate_index_cost() でファイル数・画像数(=API 呼び出し回数の目安)を課金なしで確認できます。
4-2. 完全ローカル版(APIキーが発行できない場合)
組織の規程で外部 API キーを発行できない——今回まさにこの制約に直面しました。コンペ規約は「商用API、ローカルLLM、…を自由に利用できます」「使用可能なツールは、商業利用が可能でオープンなものに限定」と明記しており、オープンウェイトモデルのローカル実行は規約が名指しで認める王道です。
| 役割 | モデル | ライセンス | 補足 |
|---|---|---|---|
| エージェント本体 | Qwen2.5-7B-Instruct(Ollama, 4bit量子化) | Apache 2.0 | JSON モードで ReAct を安定化 |
| 画像・グラフ読解 | Qwen2.5-VL-7B | Apache 2.0 | 文書 OCR 系 OSS の定番土台 |
| 埋め込み | multilingual-e5-large | MIT | GPU でローカル計算 |
| 再ランク | bge-reranker-v2-m3 | Apache 2.0 | もともとローカル |
すべて Colab 無料枠(T4 16GB)の VM 内で完結し、データは一切外に出ません。ローカル小型モデルは出力に前置きを混ぜて JSON を崩しがちなので、寛容 JSON パーサ(「まず検索します。{…}」のような出力から JSON 部分を救済)も入れました。再現性は API より強く、モデル重み固定+seed 固定で完全に同じ出力を再現できます。
正直なトレードオフも書いておきます。7B は gpt-4o クラスより品質が落ちます(計算コード生成の粗さ・グラフ数値読解の精度)。目安時間はインデックス構築1〜3時間、検証30問1〜2時間、本番100問4〜8時間。この前提で、全工程を「1問ごとに Drive へ進捗保存 → 切断されても再実行で続きから」のレジューム設計にしました。無料枠のセッション切断は「起きるもの」として設計に織り込むのが正解です。
5. 現場で踏んだ罠と、その一般化
設計どおりに書いて終わり、にはなりませんでした。重要なのは、遭遇した問題を「このファイル・この環境だけの応急処置」ではなく「同じ性質を持つ未知の状況にも効く一般規則」として実装し直すことです。汎用性が検収要件そのものだからです。
罠1: API 残高切れ(429 insufficient_quota)が大量発生。 画像 OCR のたびに弾かれ、放置するとグラフ・書式の情報が全部欠けたインデックスができてしまう。→ 一般規則: 回復不能なエラーは専用例外として検知し、途中保存して中断、再実行で差分再開。一時的エラー(500等)のリトライとは明確に区別する。
罠2: 組織で API キーを発行できない。 → 一般規則: モデル依存を1クラスに集約しておけば、バックエンド追加(Ollama)だけで全機能がローカルへ移行できる。埋め込みは最初からローカルフォールバックを用意しておく。
罠3: Ollama インストーラが zstd を要求して失敗(Colab 標準環境に未導入。インストーラ側の配布形式変更が原因)。→ 一般規則: 実行環境の前提は変わるもの。セットアップは冪等な「復旧セル」(本体確認→再インストール→サーバ起動→モデル確認→不足分 pull)として1つにまとめ、セッション切断後はそれ1つで戻れるようにする。
※OllamaのRAG作成には1時間近くかかった。

罠4: ローカル VLM への画像送信が 400 Bad Request。 原因は Office 埋め込み画像に多い WMF/EMF 形式(Windows メタファイル)を VLM が受け付けないこと。→ 一般規則: VLM へ渡す前に PIL で PNG へ統一変換・長辺縮小。デコード不能な装飾画像は恒久スキップ、読めたはずの画像で失敗したファイルは manifest 除外で次回リトライ。エラーメッセージにはレスポンス本文を含めて原因を特定可能にする。
罠5: パスワードそのものはどこにも書かれていない暗号化ファイル。 社内規定には「導出規則」だけがある。→ 一般規則: 規則文書を実行時に読み、LLM に機械適用させて候補を生成(前掲⑤)。規則の中身をコードに書かないので新規案件にも一般化される。
罠6: 日本語ファイル名の NFC/NFD ゆれ。 → 一般規則: 正規化を1箇所(パス解決マップと find ヘルパー)に集約し、エージェント生成コードにも同じヘルパーを使わせる。
6. PDCA — 6サイクルの反復
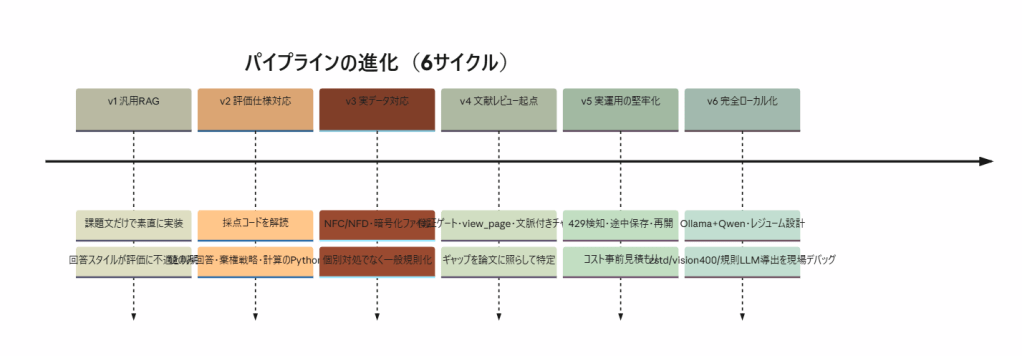
各サイクルの Act が次の Plan になっています。特に v4 は「自分の実装を先行研究に照らして棚卸しする」回で、(a) 検証ゲート未実装、(b) ページ直接参照 の欠落、(c) チャンク文脈付与 未適用、の3ギャップを特定して埋めました。文献レビュー自体を Check 工程に組み込むと、改善の打ち手が経験則ではなく再現された知見から出せます。v6 は「環境が理想でなくても動かし切る」回で、罠1〜5 の一般規則化がここに入ります。
次のサイクルは精度チューニングです。検証30問(正解つき)をローカル採点し、誤答の型(検索ミス/計算ミス/形式ズレ/棄権すべきだった誤答)を分類 → パラメータとプロンプトを調整 → 再計測。「特定の質問に合わせた調整」はルール違反なので、誤答の”型”への一般的な改善だけを行うのが鉄則です。
7. 工夫すべきポイント(まとめ)
評価器を最初に読む。 最大のレバレッジは「採点 LLM が質問文を見ない」「列挙の部分一致は -1」「Missing は 0」の把握でした。CRAG [1] が示すとおり最先端の産業 RAG でもハルシネーションなしは6割程度。何を正解とするかを先に固定するのは実務でも同じです。
期待値で棄権を設計し、検証ゲートで守る。 誤答-1/棄権0 の非対称性がある以上「自信のない列挙は答えない」は合理的で、KDD Cup 上位解 の定石。生成→検証→棄権を最後に1段入れるだけで、最も高くつく失敗を系統的に減らせます。モデルが小さいほど効きます。
LLM に算術をさせない。 集計・件数・平均・差分は必ずコード実行に落とす(PAL / PoT)。pandas を渡すだけで計算問題の信頼性が桁違いに上がります。
パースを軽視しない。 OCR・抽出のノイズは下流で増幅される(OHRBench)。形式ごとに最も正確な読み方を選び、キャプション索引+ページ直接参照 で視覚情報を拾う。VLM へ渡す画像は形式・サイズを正規化してから。
チャンクに文脈を前置する。 《案件|ファイル名|位置》の機械的前置だけでも検索が安定します(Contextual Retrieval の軽量版)。
順位ベースの融合(RRF)を使う。 学習不要・校正不要でコーパス規模の変化に強い。汎用性要件と相性が良い。
増分性と再開性を同じ仕組みで。 台帳の「失敗は載せない=次回リトライ」という1規則が、データ追加・中断再開・部分失敗のすべてを賄います。加えて回答側も1問ごと進捗保存にすれば、セッション切断が怖くなくなります。
道具立てはスコアで選ぶ。 マルチエージェントや MCP は「使えるから使う」ではなく「この採点でスコアを上げるか」で判断。今回はどちらも見送りが正解でした。
環境の罠も一般規則で潰す。 依存の変化(zstd)、形式の癖(WMF/EMF)、規程の制約(APIキー不可)——すべて「次も起きる」前提で、冪等な復旧手順・正規化層・バックエンド抽象化として実装に落とす。
8. 実装環境まとめ
- 開発・検証: Ubuntu 24 / Python 3.12。LLM・埋め込みをモックにしてネットワークなしで結合テスト(モック Ollama サーバを立て、実 HTTP 経路まで検証)
- API 版: 任意の Python 3.10+ 環境。
OPENAI_API_KEYと残高が必要。gpt-4o + text-embedding-3-large - ローカル版: Google Colab 無料枠(T4 GPU 16GB)で動作。Ollama + Qwen2.5-7B / Qwen2.5-VL-7B + e5-large + bge-reranker。APIキー・課金・外部送信なし
- 評価: 配布のローカル評価環境で提出前にスコアを見積もり可能。検証30問(正解つき)→ 本番100問の順で回すのが安全
- 規模感: 約400ファイル(docx/pptx/xlsx/pdf/ipynb/py/png等)から約1.2万チャンク。コード本体は単一ファイル約1,500行
9. 今後の拡張候補(文献ベースの伸びしろ)
意図的に採らなかった選択肢のうち、要件が変われば有力になるもの。ページ画像を直接インデックスする ColPali 系検索 は、スキャン中心・レイアウト依存の強いコーパスなら乗り換える価値があります。案件間・人物間の関係を問う質問が増えるなら GraphRAG や階層要約木の RAPTOR。巨大帳票が主戦場なら SpreadsheetLLM のシート圧縮。xlsx のセル塗り色・文字ハイライトの構造抽出(openpyxl の fill 情報等)は、書式を問う質問への次の一手です。常設ツール化するなら MCP でのサーバ公開。文書中心マルチモーダル RAG の全体像はサーベイ が出発点です。
参考文献
[1] Yang, X. et al. “CRAG — Comprehensive RAG Benchmark.” arXiv:2406.04744 (2024). [2] Xia, Y., Chen, J., Gao, J. “Winning Solution For Meta KDD Cup’24.” arXiv:2410.00005 (2024). [3] Ouyang, J. et al. “Revisiting the Solution of Meta KDD Cup 2024: CRAG.” arXiv:2409.15337 (2024). [4] “Multi-Stage Verification-Centric Framework for Mitigating Hallucination in Multi-Modal RAG”(KDD Cup 2025 CRAG-MM). arXiv:2507.20136 (2025). [5] Yao, S. et al. “ReAct: Synergizing Reasoning and Acting in Language Models.” arXiv:2210.03629 (2022). [6] Singh, A. et al. “Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.” arXiv:2501.09136 (2025). [7] Liang, J. et al. “Reasoning RAG via System 1 or System 2: A Survey on Reasoning Agentic RAG for Industry Challenges.” arXiv:2506.10408 (2025). [8] Gao, L. et al. “PAL: Program-aided Language Models.” arXiv:2211.10435 (2022). [9] Chen, W. et al. “Program of Thoughts Prompting.” arXiv:2211.12588 (2022). [10] Faysse, M. et al. “ColPali: Efficient Document Retrieval with Vision Language Models.” arXiv:2407.01449, ICLR 2025. [11] Yu, S. et al. “VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents.” arXiv:2410.10594, ICLR 2025. [12] Cho, J. et al. “M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding.” arXiv:2411.04952 (2024). [13] Wang, Q. et al. “ViDoRAG: Visual Document Retrieval-Augmented Generation via Dynamic Iterative Reasoning Agents.” arXiv:2502.18017, EMNLP 2025. [14] Zhang, J. et al. “OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation.” arXiv:2412.02592, ICCV 2025. [15] “SERVAL” — VLM生成キャプションをテキストエンコーダで索引する generate-then-encode 方式 (2025). [16] Poznanski, J. et al. “olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models.” arXiv:2502.18443 (2025). [17] Niu, J. et al. “MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing.” arXiv:2509.22186 (2025). [18] Ouyang, L. et al. “OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations.” arXiv:2412.07626, CVPR 2025. [19] Dong, H. et al. “SpreadsheetLLM: Encoding Spreadsheets for Large Language Models.” arXiv:2407.09025 (2024). [20] Anthropic. “Introducing Contextual Retrieval.” Engineering blog (2024). [21] Cormack, G., Clarke, C., Buettcher, S. “Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods.” SIGIR 2009. [22] Asai, A. et al. “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection.” arXiv:2310.11511 (2023). [23] Yan, S. et al. “Corrective Retrieval Augmented Generation.” arXiv:2401.15884 (2024). [24] Saad-Falcon, J. et al. “PDFTriage: Question Answering over Long, Structured Documents.” arXiv:2309.08872, EMNLP 2024 Industry. [25] “Scaling Beyond Context: A Survey of Multimodal RAG for Document Understanding.” arXiv:2510.15253 (2025). [26] Edge, D. et al. “From Local to Global: A Graph RAG Approach to Query-Focused Summarization.” arXiv:2404.16130 (2024). [27] Sarthi, P. et al. “RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval.” arXiv:2401.18059 (2024).